|
email: mayukh.sen13@rutgers.edu I am a first year graduate student at Rutgers Univeristy, New Brunswick pursuing a Masters Degree in Statistics - Data Science. I received my Bachelor in Technology (BTech.) degree in Electronics and Communication Engineering from Kalyani Government Engineering College, India. Through my courses, I had the opportunity to work with some fantastic professors. My coursework has enbaled me to deeply interact with concepts of statistics, Machine Learning and techniques for Data Science. I am proficient in R and Python with data management, data wrangling and statistical modelling skills. I interned at M.N Dastur & Co. Pvt Ltd with the Data Engineering and Electronics Department . Before that I worked as a Data Science Intern at MinD Webs Ventures. . I have taken courses on Probability Distributions & Statistical Inference, Data Wrangling, Linear Regression and Time Series Analysis . I am currently taking Data Management, Machine Learning and Statistical Modelling . Later I intend to take Deep Leanring and NLP courses. Beyond academics, I am a seasoned Quizzer, a professional EMCEE, avid sports fan and I play video games in my leisure time. |
.png) The MET, New York City, USA
|
{kind=link}
|
My research interests has traditionally spanned various sub-domains of Data Science and Machine Learning such as Natural Language Processing, Neural Networks, Statistical Modelling
and the like with a focus on designing efficient models for real-world applications. I have also had the opportunity to work
specifically in Long Short Term Memory(LSTMs), Temporal Convolutional Networks for Time Series Forecasting and CNNs for Medical Image Processing . Recently, I have taken a liking to semi-supervised and unsupervised Large Language Models(LLMs) and Responsible AI as well. I am currently doing extensive literature study in the offensive speech detection and hallucination of generative AI |
|
|
|
|
|
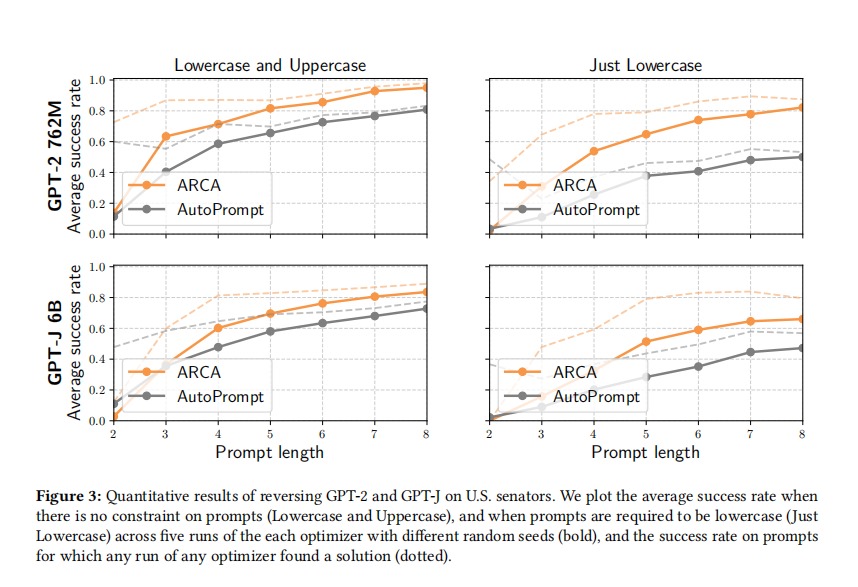
Mayukh Sen Report / slides / Code LLMs is automatically searched for input-output pairs. Audit models by specifying and solving a discrete optimization problem. We look for non-toxic prompt and toxic output pairs and exact matches for politically nuanced prompts by reversing LLMs. Used Coordinate Ascent (ARCA) for reversing LLM and log probability loss to assess LLM performance. Using gpt-2, BERT and GPT-J and Civil Comments Dataset to perform experiments and detect toxic outputs. Observed similar performance in success rate with prompt length over all LLMs denoting the effectiveness and robustness of ARCA for auditing LLMs. |

|
Mayukh Sen ,Brandon Salter , Divya Shah , Max Jacobs Report / slides / Code Built a Search App that retreives Tweets , Retweets and userinfo of users tweeting. |
|
Mayukh Sen ,Brandon Salter , Rohit Vernekar. Merck Challenge in association with Rutgers Statistics Department Report / slides / Code Neural Networks are widely considered to be "BlackBox" Models and the interpretability of Deep Learning Models are still an area of active research . In order to better understand the interpretability, my peers and I performed some experiments leveraging existing statistical methods.
We conduct experiments on MNIST Dataset and for purpose of interpretability we are working on CNN model . We also review of pretrained models on MNSIT dataset and perform Thorough analysis and evaluation of the performance on the data. Finetuning of hyperparameters to improve accuracy and performance of models.
|

|
Report slides / Code Leveraging Mistral's AI for peaceful dialogue, this project classifies text to promote understanding. It fine-tunes Mistral-7b on datasets for unity-focused content, offering tools for positive communication across digital spaces.
|
|
|
|
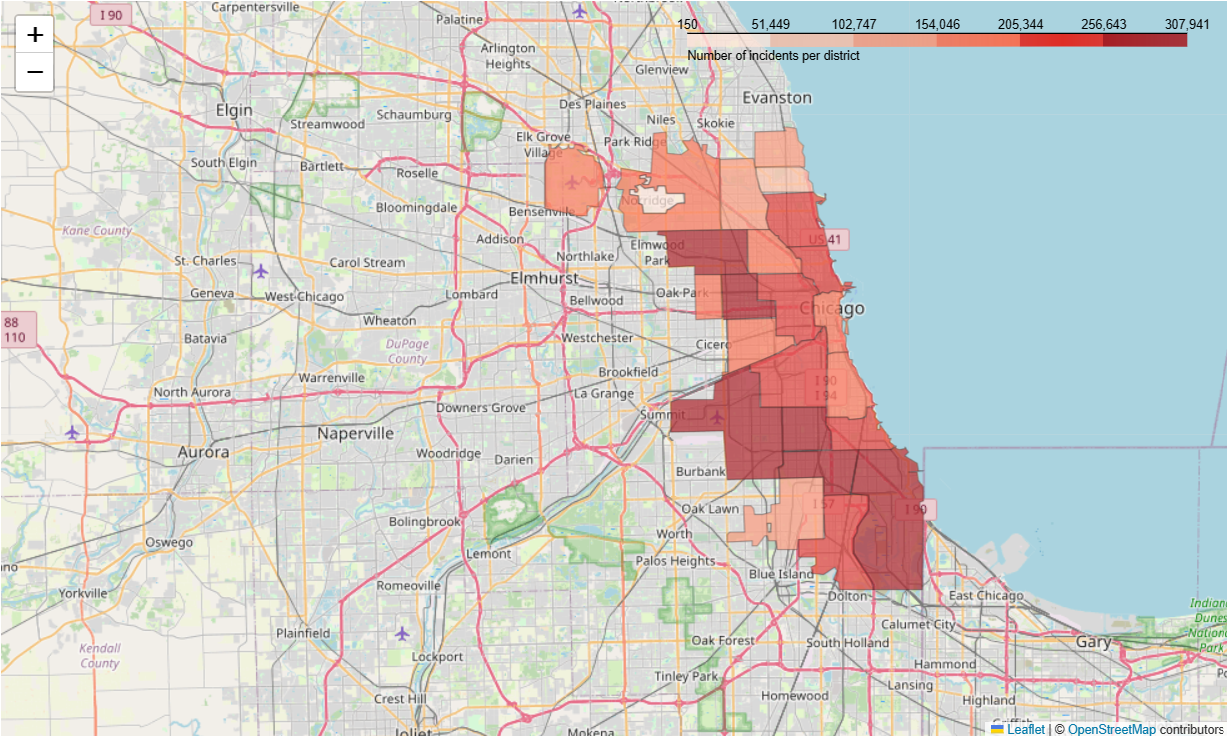
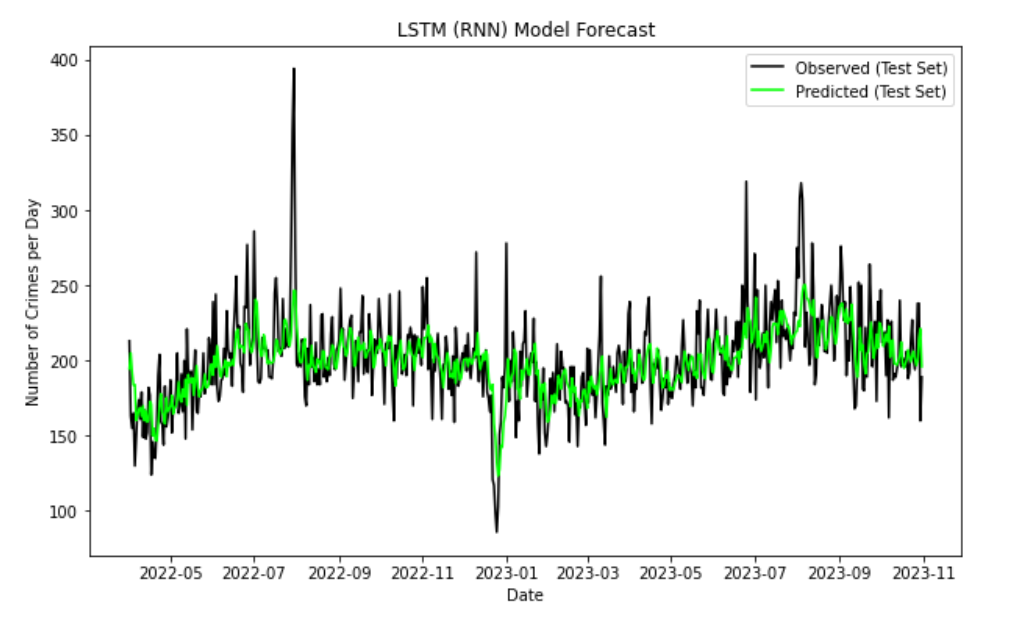
Mayukh Sen , Max Jacobs, Krish Shah Report / slides / code / dataset In this comprehensive time series forecasting project, we analyzed the Chicago Crime Dataset spanning from 2008 to 2023, which comprises 22 columns and over 4 million rows. The initial phase of the project involved meticulous preprocessing, including the removal of NA values and irrelevant columns, along with the conversion of data into appropriate datatypes. We also engaged in feature engineering to enhance the dataset's utility for analysis.
|
|
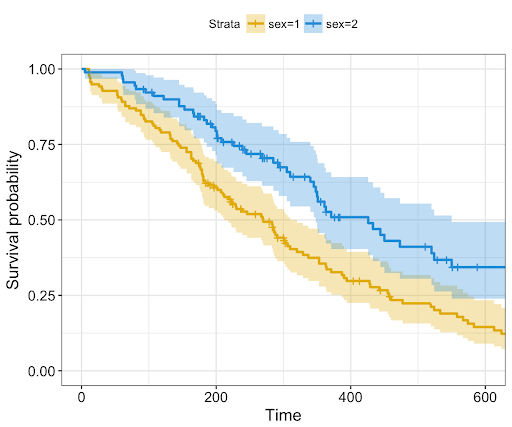
Report / slides / code Dataset In this survival analysis project, I utilized the METABRIC dataset comprising clinical profiles of 2,509 breast cancer patients to model time-to-event data, focusing on survival and relapse rates. Employing advanced statistical techniques, I conducted exploratory data analysis, preprocessing, and data cleaning, including handling missing values and label encoding. |
|
Report / slides / code / dataset
The analysis focused on the FAIR plan, a default policy offered by the City of Chicago for homeowners, using data compiled by Andrews and Herzberg (1985) and available in the R 'faraway' package. The objective was to investigate how various factors, such as race, frequency of fires, instances of theft, age of housing, income levels, and geographical location (North or South Chicago), impact the rate of policy renewals per 100 housing units.
|
|
Report / slides / code / dataset In this project, we developed a sophisticated model to predict auto insurance claim costs based on a historical dataset encompassing 22,000 entries and 22 distinct features. The data was meticulously analyzed using R, which facilitated a thorough exploratory data analysis (EDA). This process entailed comprehensive data diagnostics, insightful visualizations, and strategic feature engineering to optimize the dataset for model training.
|
|
|
|
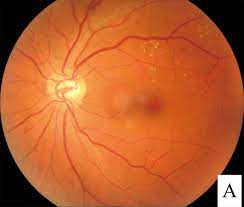
Mayukh Sen Agni Sain , Ayush Singh , Himadri Sekhar Dutta Final Year Project B.Tech Report / slides / code In this project we build an application for the identification and classification of diabetic retinopathy from fundus images of human eyes. Achieved an impressive accuracy of 96.1% in the classification of diabetic retinopathy severity levels. Trained the model while utilizing Convolutional Neural Networks(CNN) like MobileNet2, EfficientNet on Training dataset to enhance model robustness and predictive power. Employed TensorFlow, and Kerasfor modelling. Demonstrated proficiency in data preprocessing, augmentation, and transfer learning techniques. Results deployed on website built on minimalistic UI and linked using Flask API and MongoDB |
|
I have been working as a Academic Success Mentor speciliaising in Statistics. I have been an Academic Success Mentor for Thrive Student Support Services in Rutgers Univeristy, New Brunswick. My responsibilities include teaching statistics to ungergraduate students of Rutgers. I have taken sessions on Probability Distributions,Statistical Inference,hypothesis testing, Confidence Intervals, Likelihood Estimators and Bayesian Analysis etc . I have designed workshops on R and its useful statistical applications that enabled students to analytically approach statistical problems effectively and ultimately obtain stellar grades in related coursework. Also acted as an Academic Success Mentor and assisted students in developing better study habits and better understanding of subject matter through one-on-one sessions. |
|
|
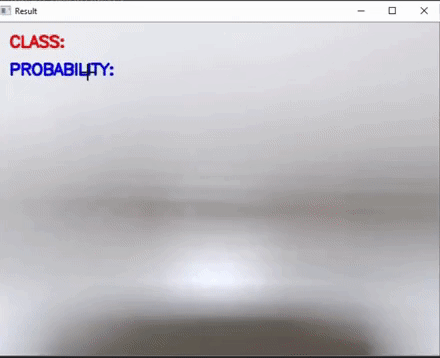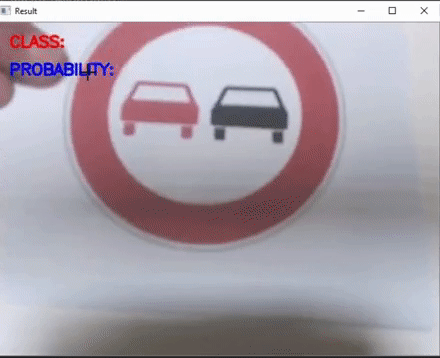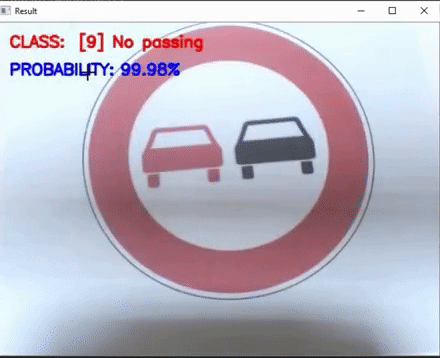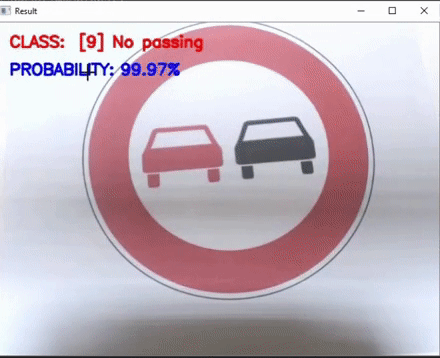 |
This work focuses on two lightweight Traffic sign classification implementations which can predict Traffic signs from any real time video feed. Here, a model based on an slightly enhanced LeNet architecture has been used and trained on the German Traffic Sign Dataset (GTSD) which has over 70000 images of traffic signs and over 40 various classes. Our model achieves a validation accuracy of over 98% and a training accuracy of over 97%. This saved model is then optimized over the Intel OpenVINO Model Optimizer + Inference Engine and run directly for predicting Traffic signs live from any video source(we have used webcam for our run). We have also provided a non optimized solution for comparison purposes. *Equal Contribution |
|
|
{kind=link}
 |
|
© Mayukh Sen (2024) | When in Rome, do as the romans do |